

置信区间,就是一种区间估计。
点估计与区间估计
游戏规则是(假设只有一个大奖):
大奖事先就固定好了,一定印在某一张刮刮卡上
买了刮刮卡之后,刮开就知道自己是否中奖
那么我们起码有两种策略来刮奖:
点估计:买一张,这就相当于你猜测这一张会中奖
区间估计:买一盒,这就相当于你猜测这一盒里面会有某一张中奖
很显然区间估计的命中率会更高(当然费用会更高,因为风险降低了)。
接下来,我们看看置信区间是如何进行区间估计的。
置信区间
我们通过对人类身高的估计来讲解什么是置信区间。
上帝视角
对于人类真实的平均身高,我们是没有办法知道的,因为几乎不可能把每个人都统计到。
但这个数据肯定是真实存在的,我们可以说,上帝知道。
在这里我们引入了上帝视角,即上帝看到的人类身高的真实分布。
假设人类的身高分布服从如下正态分布
 也就是说全体人类的平均身高为145cm,为了表示只有上帝可以看到,我把真实分布用虚线来表示:
也就是说全体人类的平均身高为145cm,为了表示只有上帝可以看到,我把真实分布用虚线来表示:
点估计
比如下面是一次抽样数据,我把算出来的样本均值(记作 图片 )画在图上(蓝色的点):

μ就是对真实的 μ 的一次点估计。
通过一次次的抽样,我们可以算出不同的身高均值的点估计:

们分辨不出哪个点估计更好:

区间估计可以改进此问题。
置信区间
置信区间,提供了一种区间估计的方法。
下面采用 95% 置信区间来构造区间估计(什么是
95% 置信区间,这个我们后面解释):

通过 95% 置信区间构造出来的区间,我们可以看到,基本上都包含了真实的 μ,除了红色的那根。
仍然不知道哪一个区间估计更好:

但是,和点估计比较:
点估计和区间估计,都不知道哪个点或者哪个区间更好
但是,按照 95% 置信区间构造出来的区间,如果我构造出100个这样的区间,其中大约有95个会包含 μ
95%置信区间
假设人群的身高服从:

其中 μ未知,σ已知。
我们不断对人群进行采样,样本的大小为 n ,样本的均值:
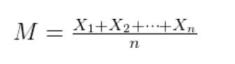
根据大数定律和中心极限定律, M 服从:

我们可以算出以 μ 为中心,面积为0.95的区间,如下图:

即:

也就是, M有 95%的几率落入此区间:

我们以  为半径做区间,就构造出了 95%置信区间。按这样构造的100个区间,其中大约有95个会包含图片:
为半径做区间,就构造出了 95%置信区间。按这样构造的100个区间,其中大约有95个会包含图片:

那么,只有一个问题了,我们不知道、并且永远都不会知道真实的 μ 是多少。
我们就只有用 ~ μ 来代替 μ :

80后