

每个子组5各数据。25个子组,分别计算Cpk和Ppk,看哪个指数大。
无非就三个答案:
1)Ppk比Cpk大;
2)Cpk比Ppk大;
3)Cpk可以比Ppk大,也可以比Cpk小;
先说答案:3)是正确的。
我们先看计算Cpk和Ppk的公式:


我们从公式可以看出,两者计算公式中除了标准差不一样,别的都一样,所以要比较两者大小,就要先理解两者所用的是什么标准差及其大小关系。
选择1)的完全不理解计算Cpk和Ppk的区别;
选择2)自己以为自己理解,实际又不完全理解;
选择3)如果不是蒙的,是真的理解了Cpk和Ppk的
区别。
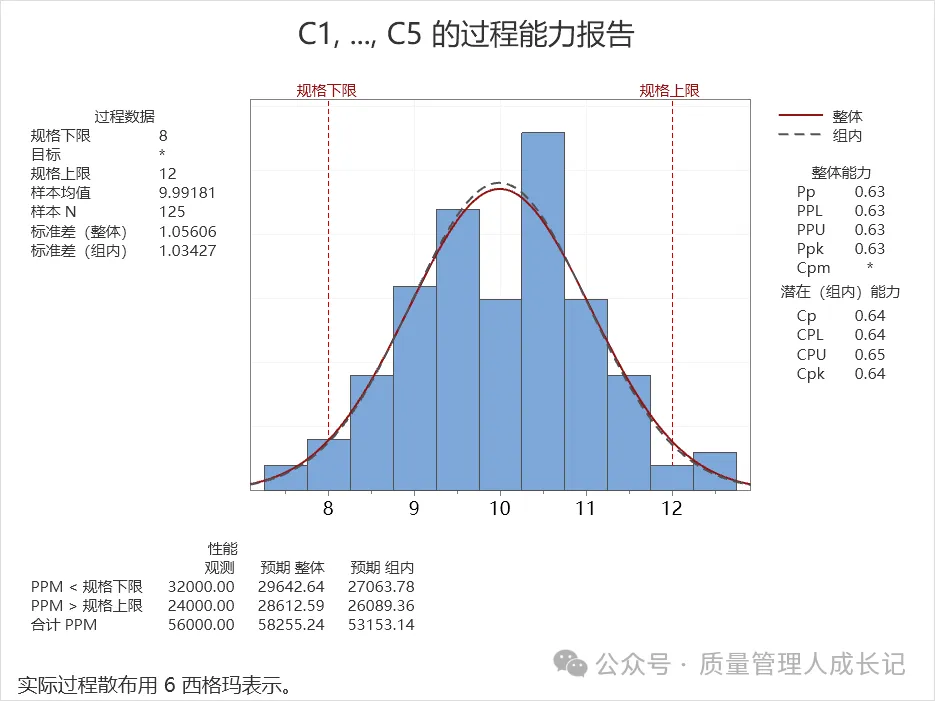
上图是常见情况:Cpk>Ppk。
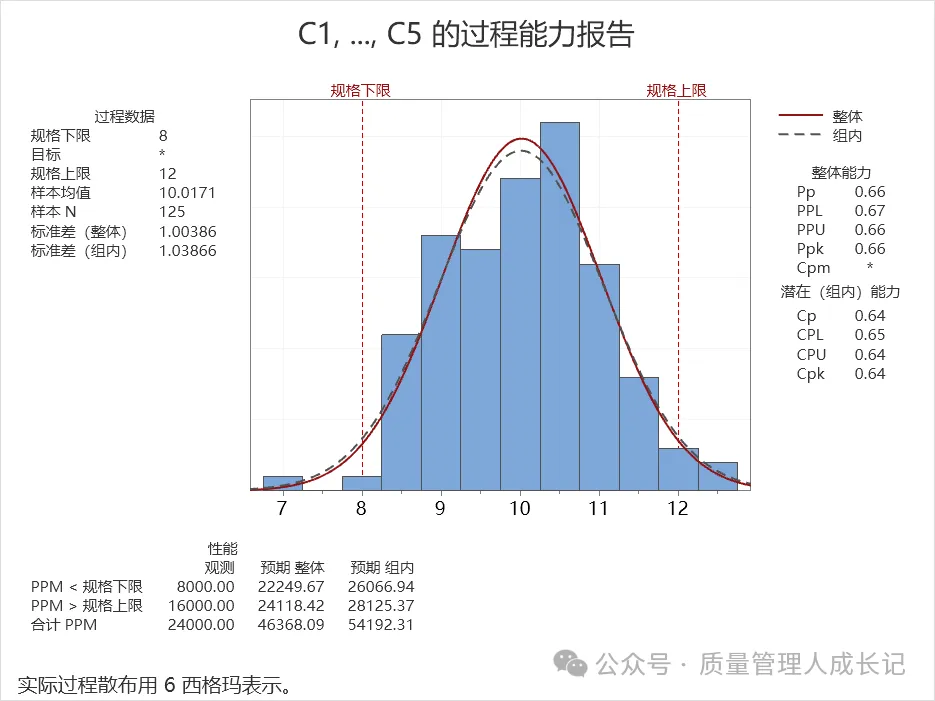
上图是Ppk>Cpk的情况。
我们通俗的理解,以均值极差控制图为例子,Cpk的计算,是用组内变差的代表:极差,除以d2常数得到过程的标准差,它是一种近似的用组内变差估计标准差的方法。
(其它类型控制图类似,也是用组内变差来估计标准差)
Ppk的计算则是实际考虑了所有样本数据的变差,不限于组内变差,也包括组间变差。
一般来说,由于Cpk只考虑了组内变差,标准差会偏小,所以计算Cpk相较于Ppk会偏大。
但是当过程统计受控,当你每次做控制图取的25个子组的数据,计算的σ和S的大小关系是不定的,也就是谁比谁大都有可能,自然Cpk和Ppk的谁大谁小也就都有可能了。
所以当你哪天发现Ppk>Cpk时,不要觉得是哪里错了,是因为数据组间变差非常小,过程统计受控了。(在此不考虑数据造假)
(内容来源:质量管理人成长记)